MOE KLINNS Lab投稿 AI解放碳基生物双手,乃至能让你的手机本身玩本身! 你没听错——这实在就是移动使命主动化。 在AI飞速发展下,这渐渐成为一个新兴的热门研究范畴。 移动使命主动化使用AI精准捕获并剖析人类意图,进而在移动装备(手机、平板电脑、车机终端)上高效实行多样化使命,为那些因认知范围、身材条件限定或身处特别情境下的用户提供亘古未有的便捷与支持。
妈妈再也不嫌重复设置多个日历事项会心烦了。 近来,来自西安交通大学智能网络与网络安全教诲部重点实行室(MOE KLINNS Lab)的蔡忠闽传授、宋云鹏副传授团队(团队重要研究方向为智能人机交互、混淆加强智能、电力体系智能化等),基于团队最新AI研究结果,创新性提出了基于视觉的移动装备使命主动化方案VisionTasker。 这项研究不但为平凡用户提供了更智能的移动装备利用体验,也显现出了对特别需求群体的关怀与赋能。  基于视觉的移动装备使命主动化方案团队提出了VisionTasker,一个联合基于视觉的UI明白和LLM使命规划的两阶段框架,用于渐渐实现移动使命主动化。 该方案有用消除了表现UI对视图条理布局的依靠,进步了对差别应用界面的顺应性。 值得留意的是,使用VisionTasker无需大量数据练习大模子。 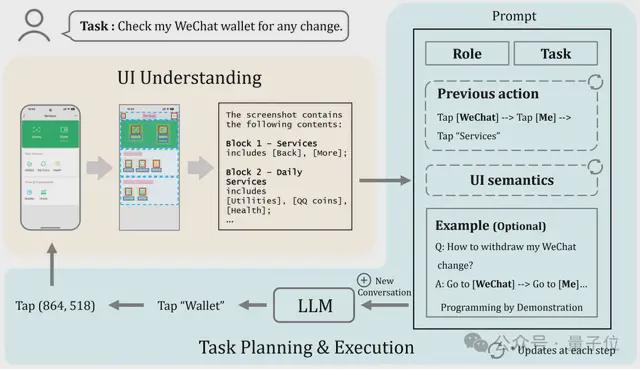 VisionTasker从用户以天然语言提出使命需求开始工作, Agent开始明白并实行指令。 详细实现如下: 1、用户界面明白 VisionTasker通过视觉的方法做UI明白来剖析息争释用户界面。 起首Agent辨认并分析用户界面上的元素及结构,如按钮、文本框、笔墨标签等。 然后,将这些辨认到的视觉信息转换成天然语言形貌,用于表明界面内容。 2、使命规划与实行 接下来,Agent使用大语言模子导航,根据用户的指令和界面形貌信息做使命规划。 将用户使命拆解为可实行的步调,如点击或滑动操纵,以主动推进使命的完成。 3、连续迭代以上过程 每一步完成后,Agent都会根据最新界面和汗青动作更新其对话和使命规划,确保每一步的决议都是基于当前上下文的。 这是个迭代的过程,将连续举行直到判定使命完成或到达预设的限定。 用户不但能从交互中解放双手,还可以通过可见提示监控使命进度,并随时停止使命,保持对整个流程的控制。 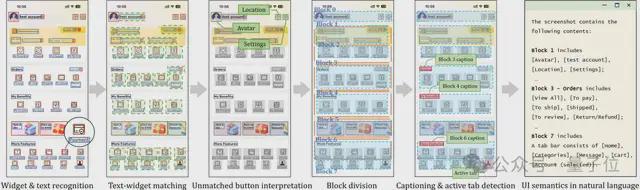 起首是辨认界面中的小部件和文本,检测按钮、文本框等元素及其位置。 对于没有文本标签的按钮,使用 CLIP 模子基于视觉计划来推断其大概功能。 随后,体系根据 UI 结构的视觉信息举行区块分别,将界面分割成多个具有差别功能的区块,并对每个区块天生天然语言形貌。 这个过程还包罗文本与小部件的匹配,确保精确明白每个元素的功能。 终极,全部这些信息被转化为天然语言形貌,为大语言模子提供清楚、语义丰富的界面信息,使其可以或许有用地举行使命规划和主动化操纵。 实行评估实行评估部门,该项目提供了对三种UI明白的比力分析,分别是:
 对比表现,VisionTasker在多个维度上比其他方法有明显上风。 别的,在处置惩罚跨语言应用时也体现出了精良的泛化本领。  △ 实行1中利用到的常见UI结构 表明VisionTasker的以视觉为底子的UI明白方法在明白息争释UI方面具有显着上风,尤其是在面临多样化和复杂的用户界面时尤为显着。 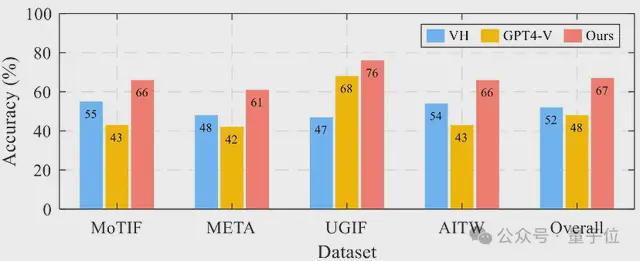 △跨四个数据集的单步猜测正确性 文章还举行了单步猜测实行,根据当前的使命状态和用户界面,猜测接下来应该实行的动作或操纵。 效果表现,VisionTasker在全部数据集上的均匀正确率到达了67%,比基线方法进步了15%以上。 真实天下使命:VisionTasker vs 人类实行过程中,研究职员计划了147个真实的多步调使命来测试VisionTasker的体现,这些使命涵盖了国内常用的42个应用步伐。 与此同时,团队还设置了人类对比测试,由12名流类评估者手动实行这些使命,然后VisionTasker的效果举行比力。 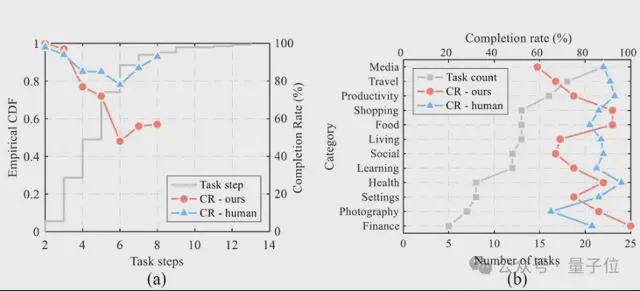 效果表现,VisionTasker在大多数使命中能到达与人类相称的完成率,而且在某些不认识的使命中体现优于人类。  △现实使命主动化实行的效果 “Ours-qwen”是指利用开源Qwen实现VisionTasker框架,”Ours”表现利用文心一言作为LLM 团队还评估了VisionTasker在差别条件下的体现,包罗利用差别的大语言模子(LLM)和编程演示(PBD)机制。 VisionTasker 在大多数直观使命中到达了与人类相称的完成率,在认识使命中略低于人类但在不认识使命中优于人类。 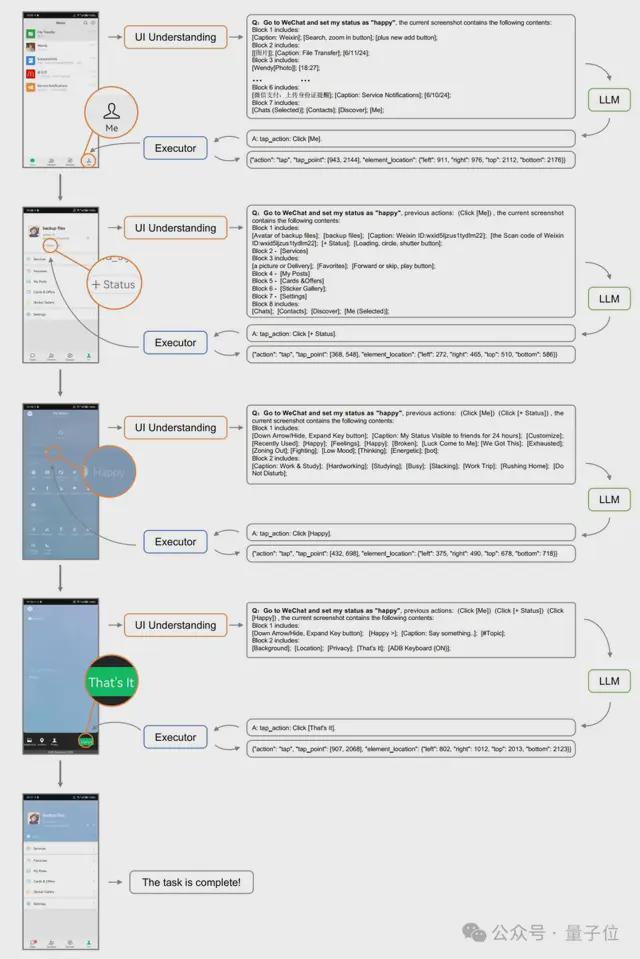 △VisionTasker渐渐完成使命的展示 结论作为一个基于视觉和大模子的移动使命主动化框架,VisionTasker降服了现阶段移动使命主动化对视图层级布局的依靠。 通过一系列对比实行,证实其在用户界面体现上逾越了传统的编程演示和视图层级布局方法。 它在4个差别的数据集上都展示了高效的UI表现本领,体现出更广泛的应用性;并在Android手机上的147个真实天下使命中,特殊是在复杂使命的处置惩罚上,体现了出逾越人类的使命完成本领。 别的,通过集成编程演示(PBD)机制,VisionTasker在使命主动化方面有明显的性能提拔。 现在,该工作已以正式论文的情势发表于2024年10月13-16日在美国匹兹堡举行的人机交互顶级集会UIST(The ACM Symposium on User Interface Software and Technology)。 UIST是人机交互范畴专注于人机界面软件和技能创新的CCF A类顶级学术集会。  原文链接:https://dl.acm.org/doi/10.1145/3654777.3676386 泉源网址:https://www.163.com/dy/article/JFRBOMOB0511DSSR.html |







